
As we delve deeper into the realm of artificial intelligence and machine learning, the quest to create more intelligent and responsive chatbots becomes increasingly important. Incorporating our knowledge into Large Language Models (LLMs) is one of the key challenges facing any company looking to apply Generative AI.
In this article we will discuss three different ways to incorporate our knowledge into existing models such as GPT4, Llama, Gemini…
Prompt engineering
Prompt engineering is a technique that has become crucial in the field of natural language processing, especially in optimizing interactions with large language models (LLMs). This approach involves the careful creation and refinement of prompts, which are inputs used to guide the model to produce desired outputs. Through prompt engineering, developers can influence the model’s responses to make them more relevant, accurate, and targeted. By experimenting with different prompt structures, including questions, statements, or instructions, developers can discover the most effective ways to communicate with the model, unlocking its full potential for a wide range of applications.
Few-shot learning is a powerful way to embed our knowledge into models with minimal examples. This approach leverages the model’s ability to learn from a limited set of examples, allowing it to apply learned concepts to new, unseen data. By presenting the model with a few carefully selected examples that illustrate the desired task or knowledge domain, few-shot learning can significantly improve the model’s performance and understanding in specific contexts.
An example of the Few-Shot Learning can be seen in the following example:
RAG (Retrieval augmented generation)
RAG solves the problem of adding custom context to Large Language Models (LLMs) by bridging the gap between the vast knowledge on which these models have been trained and the specific, sometimes niche, information required in real-time interactions. This technique enhances the model’s ability to provide responses that are not only contextually relevant, but also deeply informed by external databases or knowledge bases. By integrating RAG, developers can tailor LLM responses to better reflect the specific needs and context of their application, creating chatbots and AI systems that provide more accurate, useful, and personalized interactions.
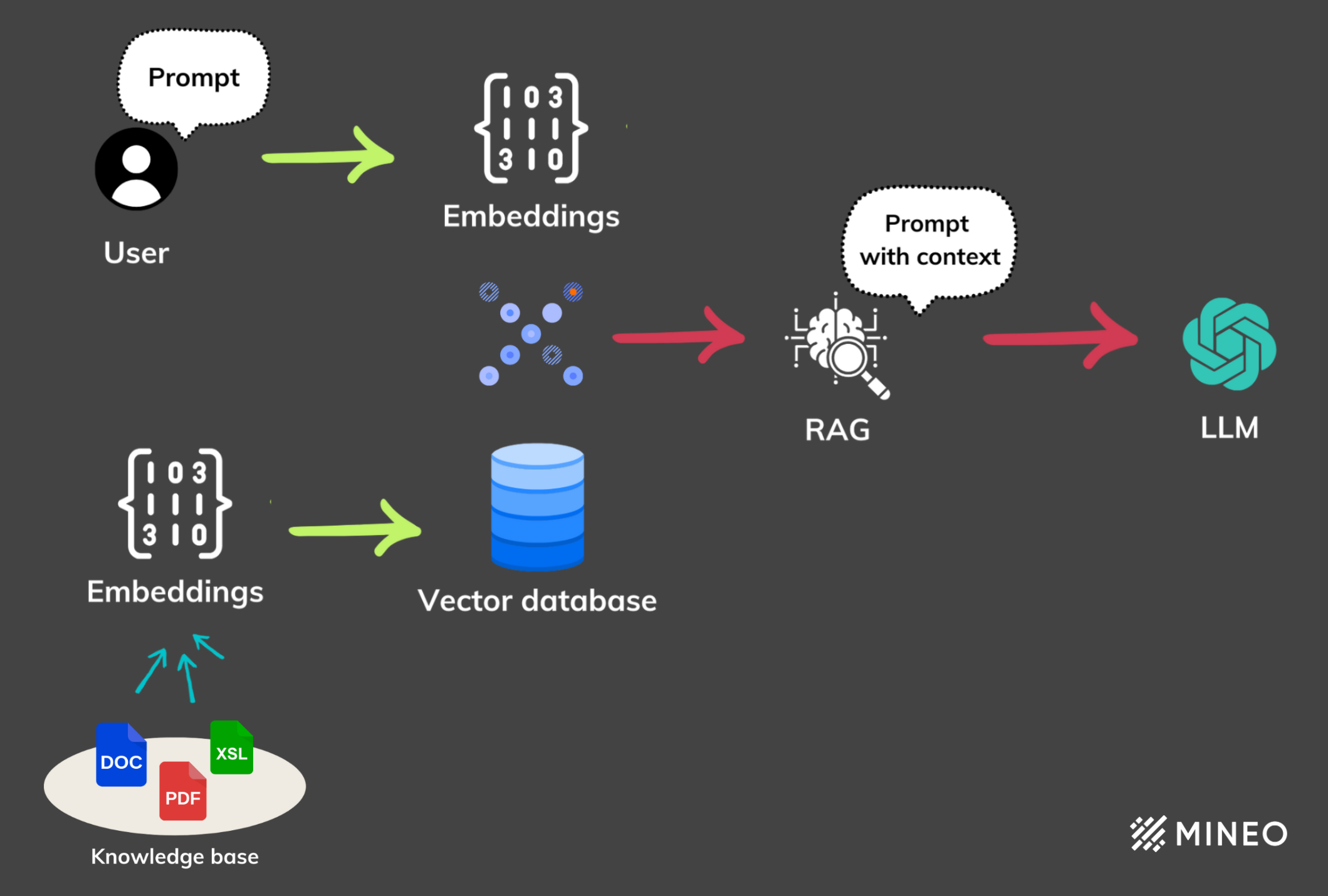
RAG (Retrieval augmented generation)
RAG works in two steps:
- The retrieval step, where the system queries a database or knowledge base to find relevant information based on the input query. This process uses advanced search algorithms to sift through large amounts of data and identify and retrieve the pieces of information most likely to inform a correct and relevant response. typically, this process involves embeddings with a distance search to retrieve data based on content rather than traditional systems.
- The second step is called generation, where the retrieved information is fed into the language model along with the original query. The model synthesizes this combined input to generate a coherent, informed, and contextually relevant response.
This two-step process ensures that RAG-enhanced models can provide answers that are not only plausible based on their training data, but also tailored to the specific query at hand, enriched with the most current and specific information available
What are embeddings?
Embeddings are a fundamental concept in machine learning and natural language processing, where words, sentences, or even entire documents are converted into vectors of numbers. These numerical representations capture the semantic meaning of the original text, allowing textual information to be compared, manipulated, and analyzed in a mathematical way. By mapping text into a high-dimensional space, embeddings enable algorithms to understand the context and relationships between words or phrases, making it possible to perform complex tasks such as text classification, sentiment analysis, and more.
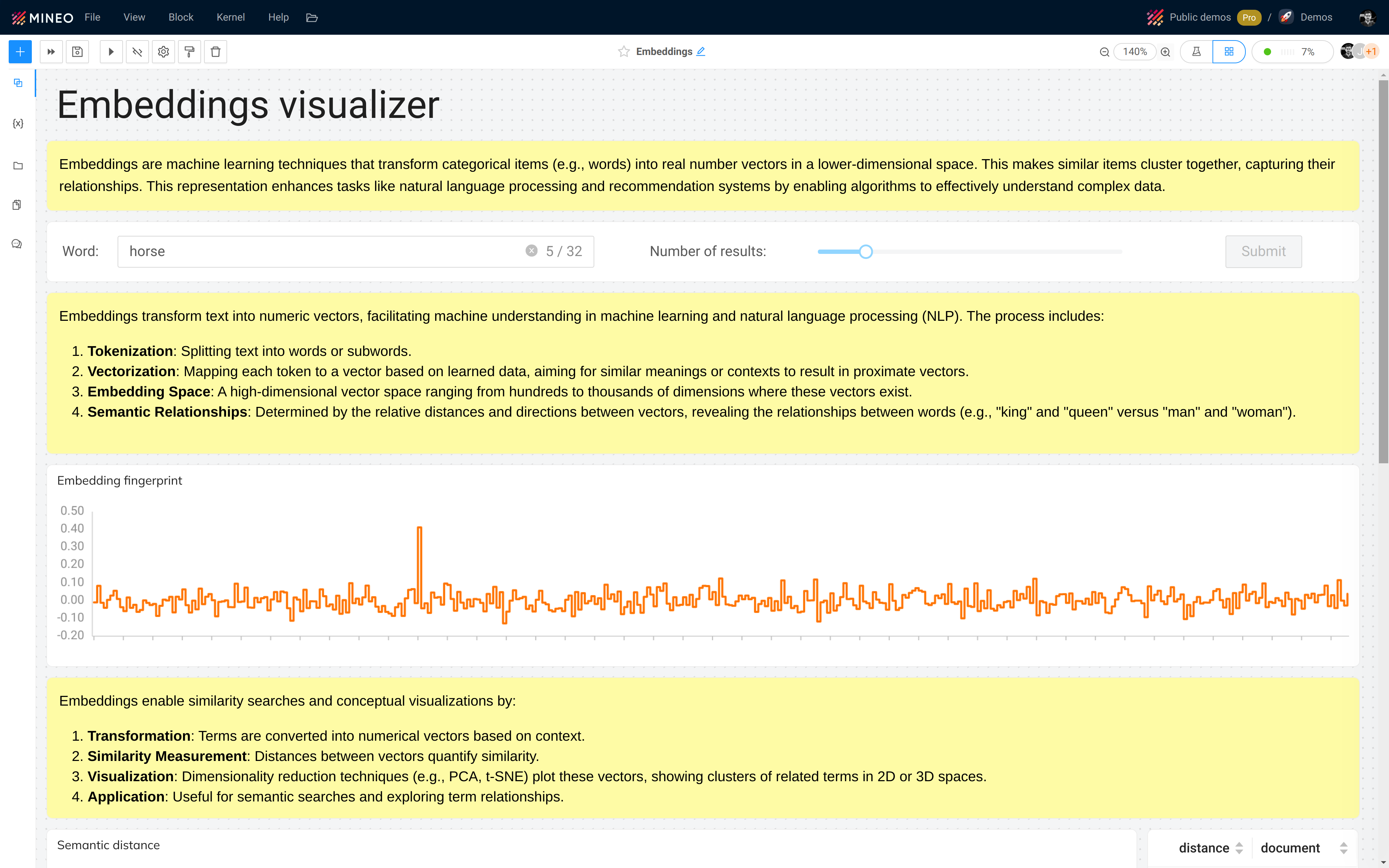
Embeddings visualizer
Explore more with embeddings the Embeddings visualizer data app.
Langchain
LangChain is an innovative open source framework designed to facilitate the development and deployment of applications based on large language models (LLMs). It aims to simplify the integration of complex natural language processing (NLP) capabilities into software solutions, making it easier for developers to leverage advanced AI for a wide range of tasks. LangChain provides a robust set of tools and functionalities that enable applications to be context-aware and reason effectively by harnessing the power of LLMs. By abstracting the complexity of working with these models, LangChain enables the rapid creation of intelligent systems that can understand, generate, and interact with human language in a meaningful way.
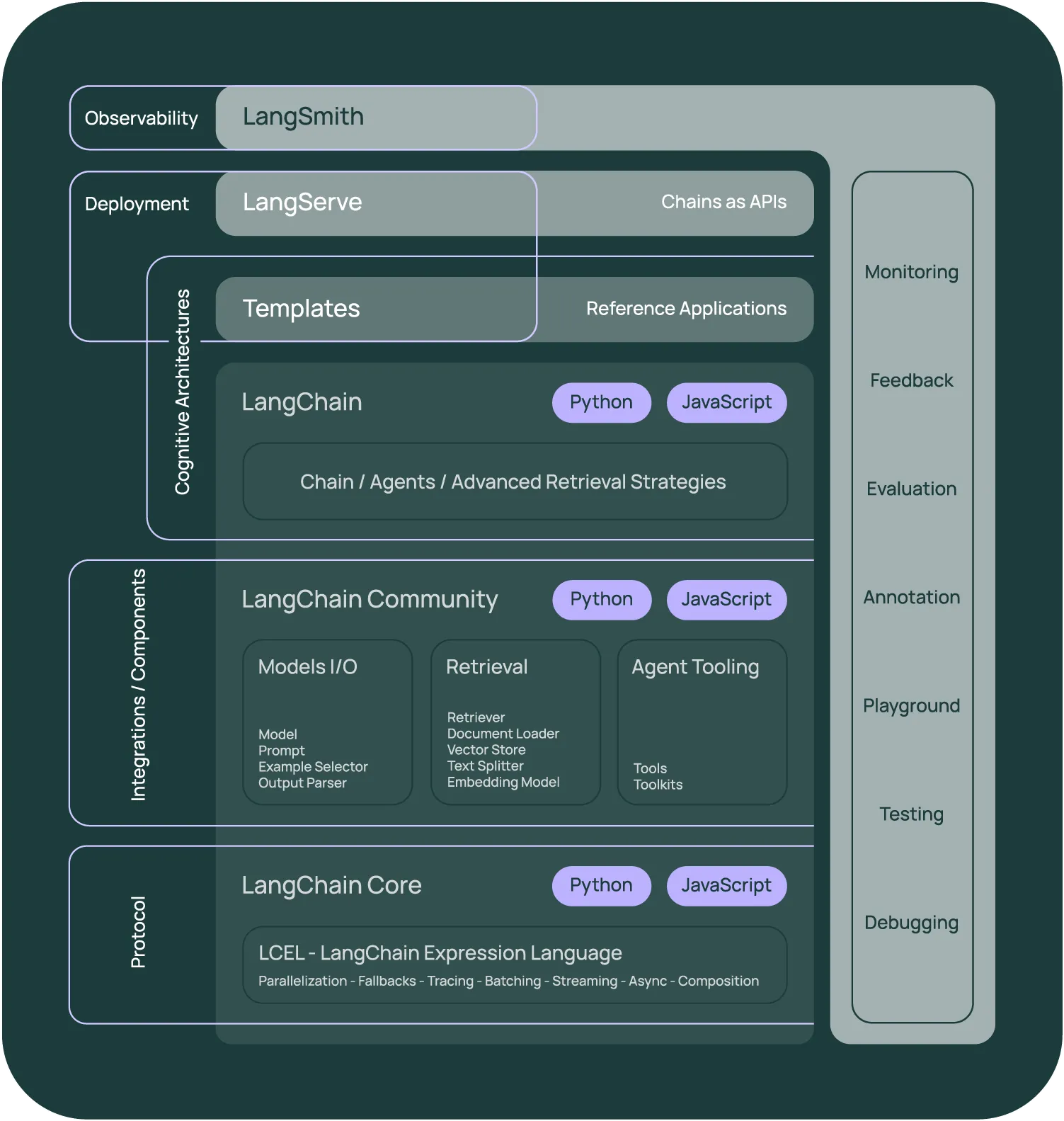
LangChain Stack
An example of a langchain built RAG is this:
If you’re interested in experiencing how a Retrieval Augmented Generation (RAG) system works in conjunction with LangChain, you can try this RAG data app implemented in MINEO.
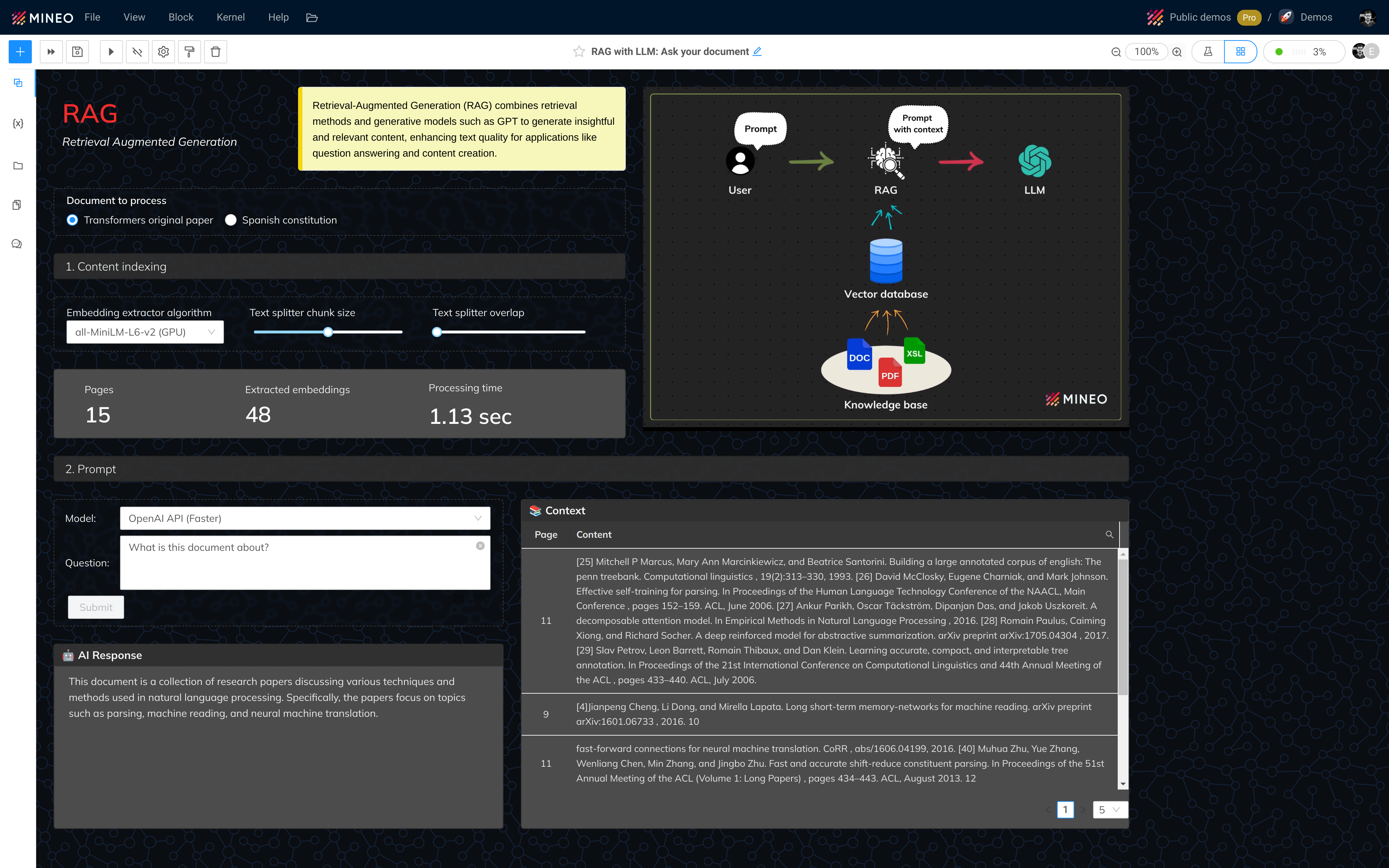
RAG Data app
Fine tuning
Fine-tuning is the third way to incorporate your knowledge into LLMs. It works by adapting an existing general-purpose model to perform better on a specific task or data set.
This method involves taking a model that has been trained on a large, diverse dataset and training it again on a smaller, specialized dataset that is relevant to the desired application. This refines the model’s parameters, making it more adept at understanding and predicting nuances specific to the new context.
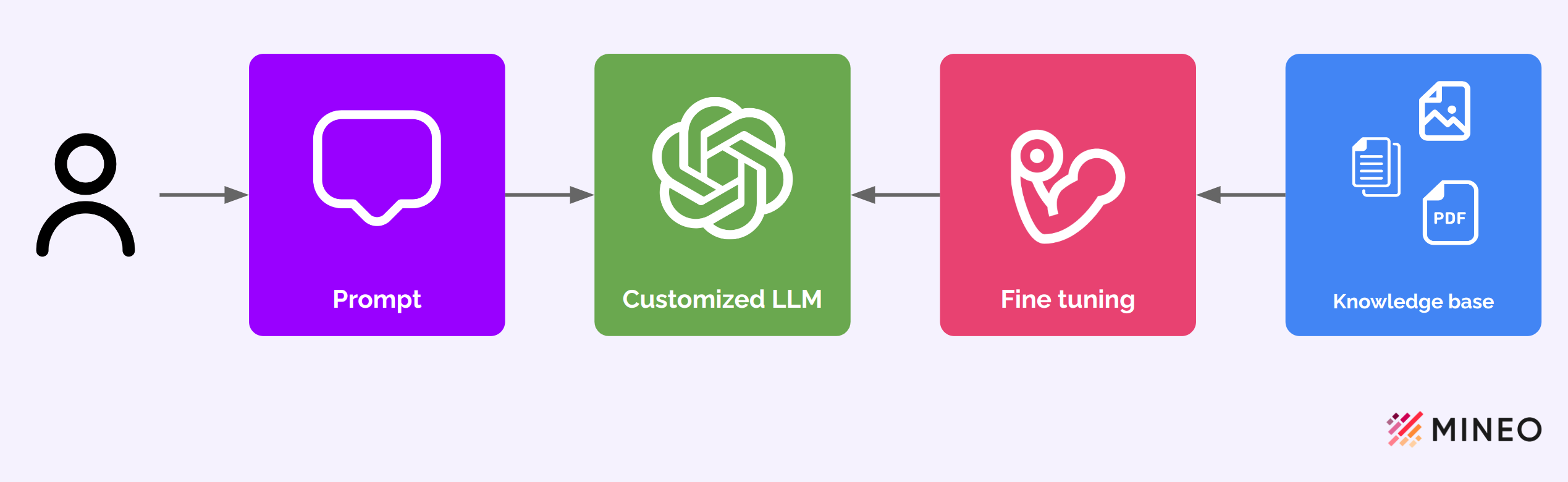
Fine-tuning process.
Fine-tuning allows large language models to be tailored to specific needs or domains, improving their accuracy and effectiveness in specialized tasks without having to build a new model from scratch. The disadvantage of fine-tuning is that it takes time and is usually expensive.
Conclusions
In summary, technologies such as RAG, prompt engineering, and fine-tuning represent critical advances in the field of artificial intelligence, particularly in extending the capabilities of large language models (LLMs).
RAG enables chatbots and AI systems to provide more accurate, contextually relevant responses by dynamically incorporating external knowledge. Prompt engineering provides a means to effectively guide these models to generate desired outcomes, while fine-tuning allows pre-trained models to be adapted to specific tasks or data sets, improving their performance in niche applications.
Together, these methods provide powerful tools for developers and researchers to incorporate their knowledge into LLMs, paving the way for more intelligent, responsive, and versatile AI applications across multiple domains.
Happy coding!